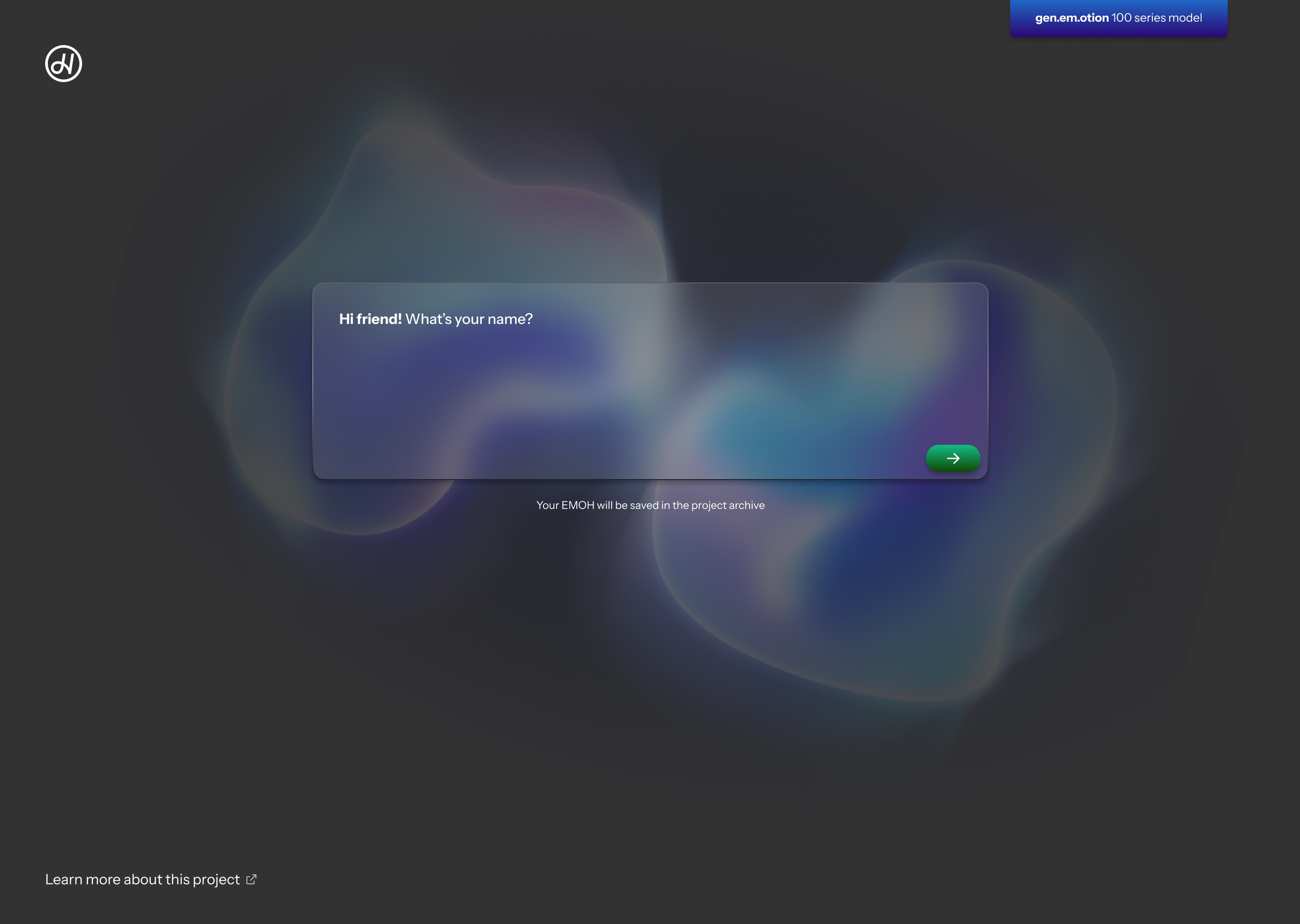
gen.em.otion
Generative AI text-to-image model based on EMOHs
I have a blog post with even more about this project!
I am building a generative image model (AKA AI image maker) that is trained off all 200+ of my works. In the end, I will have a local custom front-end to the model that will allow users to enter a prompt and generate art in my style. All locally, no cloud services involved. This model will not be publicly released, but may be shown in future gallery shows and I intend to demo it plenty and publicly online. I don’t plan on generating images in lieu of putting in the work to make my art.
Why am I doing this? Like broadcast television, the internet, smartphones, or the introduction of microcomputers to the home, I strongly believe that AI will transform the way we live and work. For better or worse. It may not look like it does right now in this AI bubble/boom we’re in, but it isn’t going away. My reasons for embarking on this project are:
- As a technologist, developer, and general nerd I want to understand what goes into crafting a generative model and have a general understanding of how “AI” works behind the scenes.
- As an artist I want to make a statement about “AI art” and I want to feel the emotions of training this model and watching it output in the style I’ve built over the last 5+ years. A style I’ve poured so much of my life, time, and heart into. I don’t know what the statement is, that’s part of the journey.
To address some concerns: Not all AI is good. Not all AI is used for good. For example, the internet is full of lifeless, meaningless AI slop you can’t escape, not to mention how AI is used by governments worldwide for unspeakable things. But AI isn’t going anywhere. We either learn how to use it, tolerate it, work with it, et cetera or we risk being left behind. I really believe that. The environmental impacts are also a huge concern to me. The model I am making is a type of generative image model called a “LoRA” model. These models are smaller and focus on something specific (like an artistic style). They then sit on top of an existing deep learning text-to-image model. My estimates are that training this model will require <24 hours of compute time when running on an Nvidia RTX4000 GPU (a consumer graphics card you can buy for gaming and daily use). Compared to training a LLM, like ChatGPT or Claude, with a massive number of power-hungry GPUs in brand-new data centers, my model’s impact is… nearly nonexistent.
Rest assured, I am thinking hard about all of this. I’m weighing pros and cons, thinking about impact, and feeling the emotions. This isn’t a frivolous project. At the end I plan to write up the details, both technical and emotional. I hope you’ll follow along.
Warmly,
Hannah A. Patellis
Some technical details for my nerds: I’m building my training dataset with the help of my art management software, Prolific. It keeps track of all the training descriptions and what pieces have and haven’t been processed. Lots of Node.js scripts are in the mix too, helping with things like image conversion, error catching, and SQL-to-TXT exporting. After the training data is ready, I’ll use DigitalOcean/Paperspace GPUs (specifically the Nvidia RTX4000) to train the model (I don’t have a device that will train a model in any reasonable amount of time and after researching I think this is the most environmentally friendly way to do it). I’ll likely use kohya_ss to build the model and then Automatic1111 to act as a backend for the generation of images. The gen.em.otion model will likely sit on top of Stable Diffusion XL 1.0 base. Finally I am building an Electron frontend that will communicate with the local Automatic1111 backend. The project will be designed to run on an Apple Silicon Mac (likely an M1 Pro Mac mini in gallery settings).